
More websites block the search engines Baidu and Yandex from indexing them than block Google. Could webmasters’ preference for Google be one of the reasons why many perceive that Google has “better search results” than their competition?
The below bar chart shows the number of websites from the Alexa top 1 million list that blocks crawling by a given search engine. The bar colors indicate the crawler’s primary market.
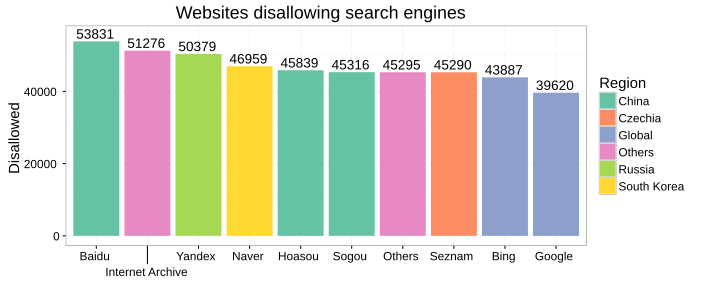
The generic “Others” column refers to the default policy applied to crawlers that weren’t specifically mentioned by name (User-agent: *.) The Chinese search engine Sogou and the Czechian search engine Seznam showing up so close to the Others category indicates that few websites have bothered with excluding them specifically.
The above numbers were gathered by collecting the robots exclusion protocol files from Alexa’s top 1 million websites and looking at what “robots” were granted access to a website. This is a small sample size out of the web’s estimated more than 1 billion active websites. I suspect that the less popular websites would be more inclined to block robots and crawlers, thus lose search engine traffic and not make it to the top one million list. Getting hold of and processing an updated list of a billion domains proved difficult, so I settled for using the top one million domains. Notably, sub-domains in which many websites relegate large portions of their content, may have separate robots files and these were not included.
I started looking into this after getting annoyed that I couldn’t find certain things in Bing and Yandex. At first, I was annoyed with the search engines for not finding some specific pages that I knew existed, and that I could indeed find with Google. However, after a while, I started looking at the robots files for these websites just out of curiosity. Lo and behold, I’d often find that the websites specifically grant access to Google while setting their default policy to deny.
The types of websites I go to might have affected this, as this would often happen with very technical websites such as code hosts and bug trackers. Most technologists seem to favor Google so that this category of websites are more likely to favor Google should probably not be a surprise.
I’m worried webmasters will lose robots.txt as a tool to control robots. A new upstart search engine that’s experimenting with their own crawler technology, like newcomer DuckDuckGo or the French Qwant.com, could never compete with the likes of Google if they were excluded from indexing a large portion of the web. I’m happy to report that not a single website blocked either of these two specifically, by their user-agents but their default deny rules would still effectively limit their indexing capabilities.
Even players that are well established in their respective markets like Baidu and Yandex must seriously be considering to either disregard the whole robots exclusion file. Or at the very least to start interpreting “Googlebot” to mean “any general-purpose search engine”.
Applebot and AppleNewsBot have already taken this approach. Quoting from Apple’s documentation: “If robots instructions don’t mention Applebot but do mention Googlebot, the Apple robot will follow Googlebot instructions.”
This approach is also followed by a few data mining services that only obey robots exclusion if their User-Agent is mention specifically. In an industry where ever more data is key to success, disregarding the default deny policy is only common business sense to keep their dataset growing.
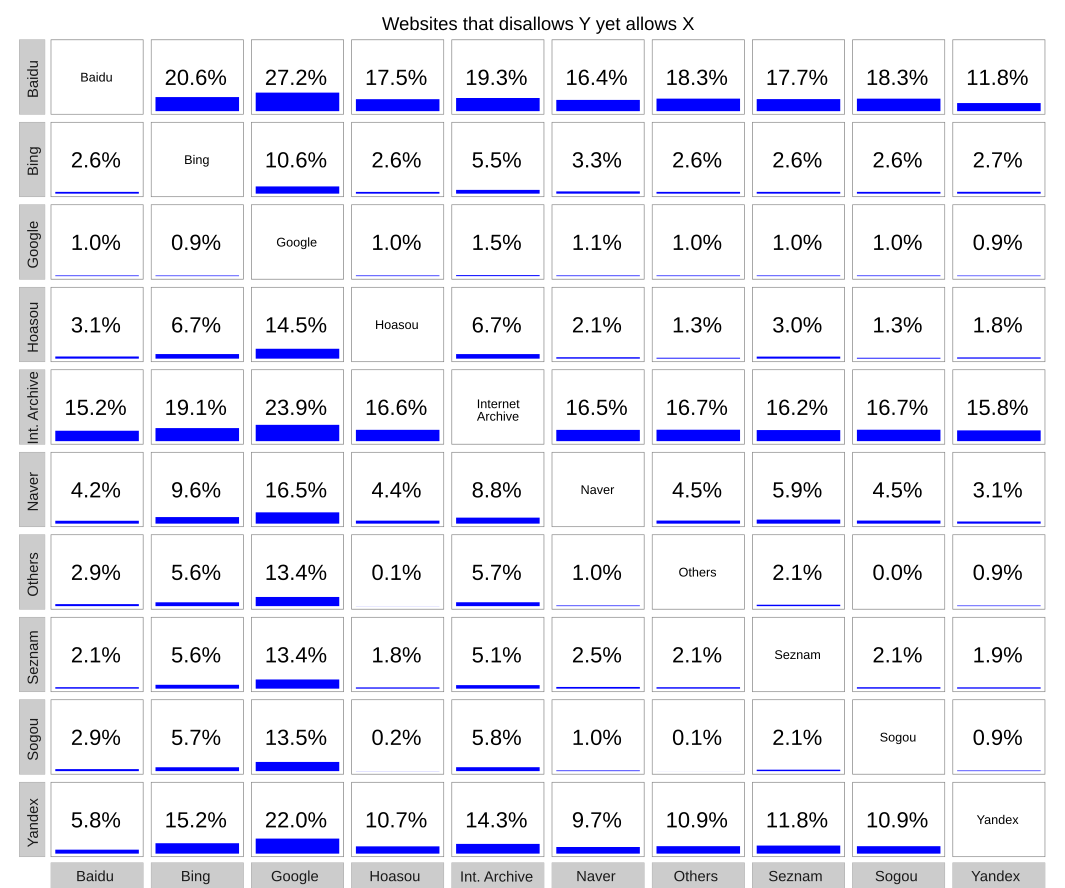
The above box grid shows the percentage of websites that block search engines on the Y-axis but allows search engines on the X-axis. From this, we can see that Googlebot gets preferential treatment on many websites that don’t allow some or all other crawlers. We can also see that many sites block Baidu and Internet Archive while allowing all other crawlers.
Google is currently controlling over 91 % of the global search market. Many reasons that let Google get into such a dominant position. They’re great for multilingual users, they’re the default search engines in many browsers and systems, and they do have a great search engine. However, 91+ % is getting very close to a global monopoly.
While researching this, I found many recipes in blogs and elsewhere around the web for creating robots.txt files that set the default policy to deny while granting a handful (or just Googlebot) of crawlers access. I’m not sure why there are so many websites blocking everyone but Google, but I do have a few theories about webmasters’ motivations.
“But my users aren’t in Russia or China! Why should I allow their crawlers?” Both Baidu and Yandex offer links to machine-translated versions of English language search results (with the translated website’s ads intact.) This opens your content up to two large markets of potential users. For many websites, eyeballs are eyeballs. Having the potential to reach new users should be more than enough motivation to allow all crawlers.
“My customers are all in the same region as me!” Sure. In that case, blocking access to search engines becomes more of a business decision. However, who is to say that American’s don’t use Yandex? or Baidu? Expats may trust their regional search engines more than Google, or just stick with their preferred search engine out of habit. If they’re looking for your business, it shouldn’t matter what tool they’re using to find you.
“My website can’t handle a few extra requests per minute.” Crawler traffic from all the large search engines will slow down automatically if they notice that the website’s response time is increasing as they crawl it. This can create an effect where websites notice high loads from crawlers that haven’t visited them before and learned the acceptable crawl rate. However, this shouldn’t normally be a problem unless the server is seriously underpowered or misconfigured. The crawler is rarely a big enough problem for this to even be a concern.
To my surprise, I haven’t been able to find any other writing on this subject except for “Googlebot monopoly: Please don’t block everything but Googlebot in robots.txt” by Dan Luu from last year. He brought up the problem with old websites that goes offline but that prohibited the Internet Archive from saving copies of them for future reference.
The Internet Archive isn’t a search engine like the other crawlers mentioned in this article. It keeps copies of old webpages around to preserve them for the future. Their robot was included in the dataset because of how many websites single them out in their robots exclusion file.
The total sample size is only 918 439 out of Alexa’s top 1 million websites. Websites without a robots.txt file are assumed to default to allow every robot. The remainder either experienced server problems, returned another type of file entirely, or had so severe parsing errors that the file would be disregarded by crawlers. Also note that the top domains don’t account for any potential content-rich subdomains, such as “blogs.”, “bugs.”, “news.” etc.
Websites were tested as either allowing or disallowing general-purpose indexing based on whether or not their robots file would allow a request to be made for a path consisting of a unique string under their root. A generic web browser-like User-Agent was used to retrieve the robots file, which was then parsed and processed against the User-Agents of known search crawlers. The tested robot names were Googlebot, Bingbot, Yandex and YandexBot, SeznamBot, HoaSouSpider and 360Spider, Baiduspider, Sogouspider, Yeti (Naver), and ia_archiver (Internet Archive.) Search engines that don’t have their own crawlers but rely on search results provided by others aren’t included.
I acknowledge that the data is incomplete at best and only considers what is found in the /robots.txt file. Application firewalls and security policies on an unknown percentage of the tested servers will outright block the User-Agents and IP addresses used by some bots. This wasn’t accounted for at all in this article.
Update (): The data on Bing is off on approximately 2000 websites. Bing was only tested with their new crawler name “Bingbot”. Bingbot, however, also respects the legacy name “msnbot” in robots.txt files.