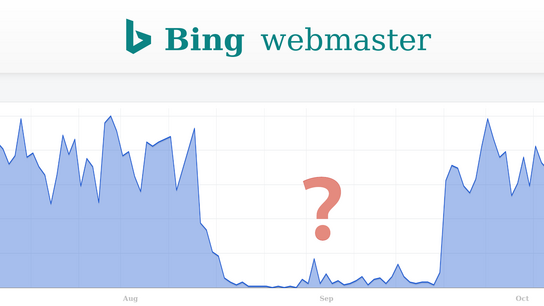
Ctrl blog was nowhere to be found in the Bing search-index for the entire month of . This lead to a decline in new readers referred from DuckDuckGo and other Bing-powered search engines.
It may not appear as Bing matters as only 2 % of monthly readers come from Bing. However, the Bing index does matter. About 5 % of monthly Ctrl blog readers come from DuckDuckGo. DuckDuckGo is a meta-search engine that combines the results from multiple search indexes to power their search results.
DuckDuckGo’s ranking is heavily influenced by Bing and I lost almost all traffic coming from DuckDuckGo when Bing had delisted Ctrl blog. There was still a trickle of readers coming in via results in DuckDuckGo. This was mostly due to DuckDuckGo’s use of search results from Yandex — an independent search index based in Russia.
The delisting from Bing also impacted the admittedly smaller number of readers coming from AOL Search, Ecosia, SearX, and Yahoo! Search. Combined, these account for another 0,6 % of monthly readers.
Ctrl blog’s archive search is was powered by Qwant, which in turn is powered by Bing. (Qwant refuses to admit this, but that’s a story for another time.) When Ctrl blog dropped out of Bing, Qwant stopped showing any search results and the archive search form stopped working.
All in all, roughly 8 % of monthly readers discover Ctrl blog through Bing.
I don’t know what caused Ctrl blog to be delisted. I reached out to Bing Webmaster Support. They couldn’t offer more information than what was available in the Bing Webmaster self-service Tools. I was told they couldn’t answer questions about individual websites, and that was that.
The Bing Webmaster Tools didn’t indicate any new problems with my site. It showed that every page I expected to be indexed was indexed successfully (even though the page didn’t show up in real search results.)
I don’t know for sure what the issue was. However, I suspect the problem may have had something to do with URL canonicalization.
A canonical URL is the preferred URL address representation for a single unique webpage. I kept an eye on the search results for the site-specific special query site:ctrl.blog on Bing every day while Ctrl blog was delisted. This search query should return every indexed page from the Ctrl blog domain.
The query returned 0–100 results every day. What was odd about the results was that they never pointed to any of my preferred canonical URLs. Instead, they’d point to variations of it. Like, the canonical URL but without the .html file extension, with a ;sf suffix, or with some kind of URL query parameters at the end of the URL. These variants ranked low on search result pages and were usually gone within another day or two.
I recognized most of the URL variants that Bing would put up in place of the canonical ones. I’ve changed domains and restructured URLs a few times over the years.
However, I’ve always been careful to create permanent redirects from every old URL to their new home. These are maintained for years. I also follow best-practice like including a <link rel="canonical"> hint on every page (RFC 6596.) The correct canonical URL is also included in the XML sitemap and other discovery mechanisms.
So, what was causing Bing trouble with indexing my pages? I don’t know for sure but I may have identified the underlying problem. If you follow this blog regularly, then you may recall that I’ve been experimenting with ways to shrink the page-weight of the metadata in the <head> element.
One of the methods I’ve been experimenting with is reducing the number of unique elements by combining duplicate elements. To make a long story short: some HTML attributes — like class, rel, and property — can contain a single value or an unordered list of space-separated values. I ended up with an element like this:
<link rel="canonical something-else">This is perfectly valid HTML, but I suspect it may have triggered a bug with Bing’s search crawlers. I’ve previously written about similar problems with Facebook and Twitter’s poor-quality RDFa parsers for Open Graph metadata.
I left one page with the two-value link element and reverted the change on every other page. Almost all pages on Ctrl blog reappeared in the Bing index days after I reverted the above change and made sure the rel attribute only contain a single value.
I don’t know for sure whether this indeed was the problem. The single page with the two-value link element didn’t reappear in the index. That doesn’t necessarily mean anything, though. A few other pages also didn’t get re-indexed and are still delisted.
Publishing a webpage can sometimes feel like you’re preparing and leaving an offering to the Internet Gods. You try to please a higher power that you don’t truly understand. The Internet Gods control whether what you publish is seen by a million people, hundreds, ten, or maybe none at all. All you can do is pray and hope you won’t offend them.